
Latest News

Pakistan Faces LNG Crisis: Can Qatar Save Them from Oversupply Disaster?
Pakistan is in a precarious situation, facing an LNG oversupply crisis as it seeks help from Qatar. By 2026, Pakistan aims to divert 24 LNG cargoes to the inter ...

Gold Prices Soar—Will Indians Still Splurge on Jewelry This Diwali?
With Diwali around the corner, the jewelry market in Delhi is buzzing, despite soaring gold prices exceeding $1,440 per 10 grams. While many are concerned about ...

Unbelievable Breakthrough: This Classic Material Could Revolutionize Quantum Tech!
Could barium titanate be the key to the future of quantum technology? Penn State researchers have found that by manipulating this classic material, its ability ...

Trump's Bold Promise: Could Weight-Loss Drugs Really Drop to $150?
President Trump has stirred excitement by suggesting a potential drop in the prices of popular weight-loss drugs to $150 per month, a significant change for man ...

China Calls Dutch Government a 'Pirate' Over Semiconductor Seizure – What's Next?
China has fiercely criticized the Dutch government's takeover of semiconductor firm Nexperia, calling it 'piracy' and threatening economic retaliation. This esc ...
Unbelievable Threat: Fungal Pathogen Could Devastate Global Wheat Supply!
Imagine a world where a single fungus puts global food security at risk. Bipolaris sorokiniana, the notorious fungal pathogen behind wheat leaf blight, is emerg ...

Isak Andic's Death: Was It Truly an Accident? Shocking Suspicions Arise!
Isak Andic's tragic death while hiking has turned into an investigation of potential homicide, with his son Jonathan now a suspect due to inconsistencies in his ...

Unbelievable Cosmic Blast: Scientists Discover the Longest Gamma-Ray Burst Ever!
In a groundbreaking discovery, astronomers recorded the longest gamma-ray burst, GRB 250702B, observed on July 2, 2025. Unlike typical bursts that last only min ...

Unbelievable: Dormant Volcano in Iran Awakens After 710,000 Years!
A dormant volcano in Iran, Mount Taftan, is showing signs of activity after 710,000 years of silence. Experts warn that pressure is building beneath the surface ...

Unbelievable: Lasers Now Transmit Power Over Five Miles without Wires!
Unbelievably, U.S. researchers have successfully transmitted electricity via laser over 5.3 miles, converting it into usable power at the receiving end. This gr ...

Is Elon Musk’s $1 Trillion Pay Package the Ultimate Power Move or a Shareholder Nightmare?
Elon Musk's proposed $1 trillion pay package is causing a stir, facing opposition from ISS, which warns of potential risks for shareholders. While it aims to lo ...

Trump's Unbelievable 100% Tariff Threat: Will It Spark a Trade War? #AINews
Could President Trump's outrageous 100% tariff on Chinese goods send shockwaves through the economy? As tensions simmer, Trump blames China for escalating trade ...

Revolutionary Artificial Neurons: Are We One Step Closer to Brain-Like AI?
In a stunning advance, researchers at the University of Massachusetts Amherst have created artificial neurons using protein nanowires from bacteria, mimicking r ...

MrBeast's Shocking Move: Is He About to Take Over Banking and Crypto?
What if your favorite YouTuber could also help you manage your money? MrBeast, the YouTube megastar known for his incredible cash giveaways, has filed a tradema ...

Are Space Hurricanes the Next Global Threat? Shocking New Findings Revealed!
Could space hurricanes be the next global threat lurking beyond our atmosphere? These cosmic storms, formed by the interaction of solar winds and Earth’s magn ...

Earth's Mysterious Origins Unveiled: Shocking Discoveries from MIT's New Research!
Uncovering the secrets of our planet's origins, MIT researchers have found rare traces of 'proto Earth,' the ancient precursor that existed about 4.5 billion ye ...

Unbelievable Online Scam Network Exposed: $15 Billion Frozen in Global Takedown!
The UK and US have taken unprecedented action against a sprawling online scam network, sanctioning 146 individuals linked to the Prince Group, led by the elusiv ...

Unbelievable Discovery on Titan: Chemistry's Rules are Being Rewritten!
In a groundbreaking discovery, scientists have unveiled that certain polar and nonpolar substances can combine under Titan's extreme cold, challenging long-stan ...

India Unveils Its First Electric Highway: A Game-Changer for Green Freight!
Get ready for a revolution in transport! On October 17, 2025, Maharashtra’s Chief Minister Devendra Fadnavis inaugurated India’s first electric highway corr ...

Revolutionizing Farewells: Singapore's Funeral Guru Launches Life-Changing Platform
Imagine having to plan a funeral while grappling with grief. Singapore's Funeral Guru is here to change that by offering a revolutionary digital platform that s ...

Unbelievable Charges: Ex-Trump Adviser John Bolton Accused of Sharing Classified Secrets!
Former Trump adviser John Bolton faces 18 counts related to storing and sharing classified information. Accusations arise from his securing top-secret documents ...

Unbelievable Discovery: Black Holes Tear Apart Stars Far From Galaxies!
Did you ever think a black hole could rip apart a star far from its galaxy? Scientists have just witnessed this incredible occurrence for the first time! An int ...
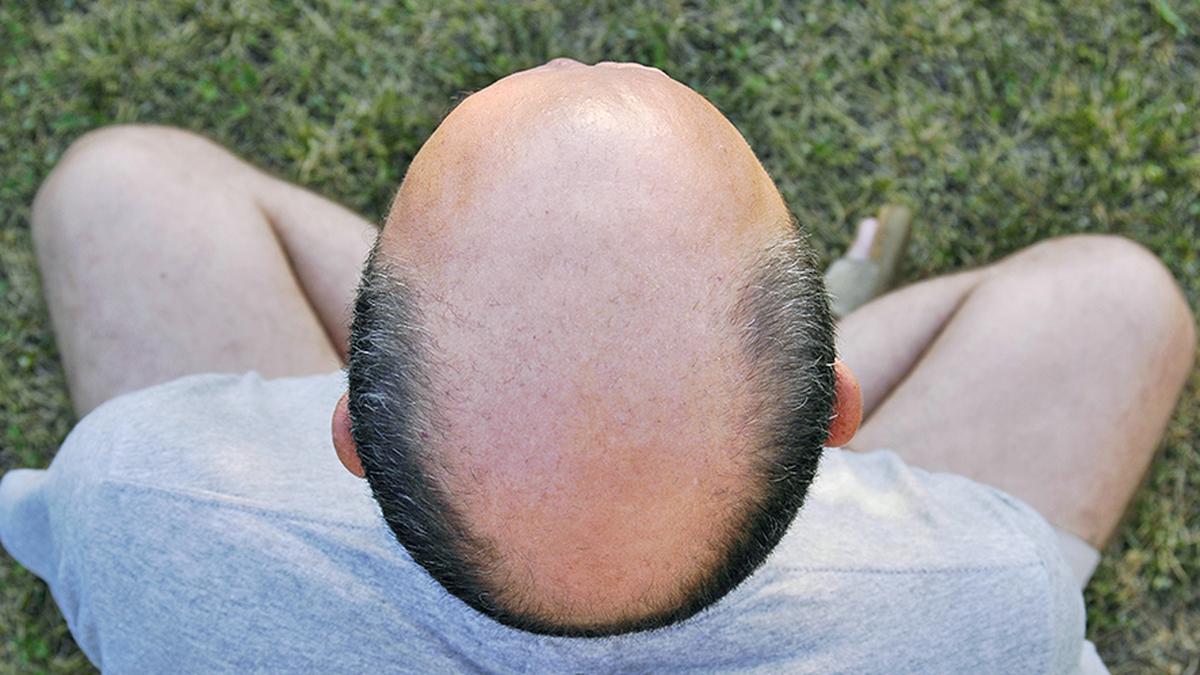
Shocking Truth: Men Are Risking It All for Miracle Hair Cures!
In an alarming trend, men are falling prey to fraudulent miracle hair cures, driven by anxiety over hair loss. Sharan, a 27-year-old from Hyderabad, found himse ...

The Hidden Battle for Rare Earths: Why Global Powers Are Scrambling for Control!
The global rush for rare earths—a group of vital minerals like europium and cerium—is shaping international trade and diplomacy. With China controlling a st ...

Half of Weight Loss Jabs Are Fake! Are You Injecting Poison into Your Body?
Would you inject unknown chemicals into your body? A staggering number of weight loss injection users in the UK are doing just that by turning to the black mark ...

Deadly Carbon Monoxide Risk: Major Recall of Vesta Tankless Water Heaters!
A major recall of Vesta tankless hot water heaters has been issued due to cracked exhaust ducts, which pose a serious risk of carbon monoxide poisoning. Health ...

China’s Shocking New Trade Move: Are We Facing a Rare Earths Crisis?
China's new export restrictions on rare earths have sent shockwaves through global trade, reminding the world of its economic power. This move has escalated ten ...

Northern Lights Could Dazzle 15 States This Week: Are You Ready?
Get ready for an unexpected cosmic treat! The Northern Lights, usually seen only in the colder northern latitudes, are set to illuminate the skies across 15 U.S ...
China's Iron Ore Ban? A Battle for Control That Could Change Global Trade Forever!
Could a simple dispute between BHP and China’s CMRG transform global trade? As negotiations heat up, the potential for China to impose a ban on BHP iron ore s ...

CEO's Wild Spending on Girlfriends Sparks Legal Battle—Is Love Really Worth €100,000?
In an astonishing courtroom battle, HansaWorld CEO Karl Bohlin's extravagant spending on women has sparked serious allegations from COO Jennifer Carroll. With c ...

Ancient Chewing Gum: The Surprising Secret to Neolithic Life Revealed!
Unbelievably, chewing gum has deep roots in our history! A new study from the University of Copenhagen reveals that birch bark tar, the world's oldest synthetic ...

Unbelievable Ice Age Secrets: Sea Level Changes Were Happening All Along!
Ever wondered how much we really know about the ice ages? A new study reveals that significant sea level changes occurred throughout the last ice age, not just ...

Why Did Neanderthals Disappear? Shocking Mini-Brain Research Reveals Secrets!
Could mini-brains hold the key to understanding why Neanderthals disappeared? Researchers at UC San Diego are growing organoids to uncover this evolutionary mys ...

Shocking Rise: How AI is Empowering Cyberattacks Against America!
As nations like Russia, China, Iran, and North Korea hone their cyberattack strategies with artificial intelligence, the stakes for U.S. companies and individua ...

Unbelievable Discovery: The Most Pristine Star Ever Found—What It Means for Our Universe!
In a groundbreaking discovery, astronomers have identified a red giant star named SDSS J0715-7334, which boasts the lowest metallicity ever recorded. Found near ...

Unbelievable Discovery: Mars' Surface Reshaped by Burrowing Dry Ice Blocks!
Unbelievably, Mars' surface is being reshaped by blocks of dry ice that burrow like living organisms! A new study reveals that these blocks create sinuous chann ...

Why Diwali Treats Are Becoming a Luxury: Dry Fruit Prices Skyrocket!
As Diwali approaches, the prices of dry fruits have skyrocketed, making them unaffordable for many. Due to festive demand and import disruptions linked to tensi ...
Unbelievable! The Pixel 10 Pro Fold is the Weakest Folding Phone Ever Tested!
Hold onto your seats! The Pixel 10 Pro Fold is being called the weakest folding smartphone ever tested, according to tech reviewer Nelson. From a scratched cove ...

Scientists Discover a Shocking New Phase of Ice That Could Change Everything!
Scientists have made a stunning discovery by identifying a new phase of ice, known as Ice XXI, which expands the known phases of ice to 21. By supercompressing ...
News by Category
Pakistan Faces LNG Crisis: Can Qatar Save Them from Oversupply Disaster?
Pakistan is in a precarious situation, facing an LNG oversupply crisis as it seeks help from Qatar. By 2026, Pakistan aims to divert 24 LNG cargoes to the inter ...
Gold Prices Soar—Will Indians Still Splurge on Jewelry This Diwali?
With Diwali around the corner, the jewelry market in Delhi is buzzing, despite soaring gold prices exceeding $1,440 per 10 grams. While many are concerned about ...
Trump's Bold Promise: Could Weight-Loss Drugs Really Drop to $150?
President Trump has stirred excitement by suggesting a potential drop in the prices of popular weight-loss drugs to $150 per month, a significant change for man ...

Unbelievable Footprints Reveal Ancient Hominins Walking Side by Side!
Unbelievably, researchers at Lake Turkana have discovered ancient footprints revealing two species of hominins walking side by side 1.5 million years ago. This ...
Unbelievable Threat: Fungal Pathogen Could Devastate Global Wheat Supply!
Imagine a world where a single fungus puts global food security at risk. Bipolaris sorokiniana, the notorious fungal pathogen behind wheat leaf blight, is emerg ...
Unbelievable Cosmic Blast: Scientists Discover the Longest Gamma-Ray Burst Ever!
In a groundbreaking discovery, astronomers recorded the longest gamma-ray burst, GRB 250702B, observed on July 2, 2025. Unlike typical bursts that last only min ...
Unbelievable Breakthrough: This Classic Material Could Revolutionize Quantum Tech!
Could barium titanate be the key to the future of quantum technology? Penn State researchers have found that by manipulating this classic material, its ability ...
Unbelievable Charges: Ex-Trump Adviser John Bolton Accused of Sharing Classified Secrets!
Former Trump adviser John Bolton faces 18 counts related to storing and sharing classified information. Accusations arise from his securing top-secret documents ...
Unbelievable! The Pixel 10 Pro Fold is the Weakest Folding Phone Ever Tested!
Hold onto your seats! The Pixel 10 Pro Fold is being called the weakest folding smartphone ever tested, according to tech reviewer Nelson. From a scratched cove ...